Vertrouwen op Wikipedia: waar komt dat vandaan? Iedereen weet dat de informatie op Wikipedia over het algemeen van hoge kwaliteit is, maar door de open structuur kun je nooit helemaal zeker zijn van de betrouwbaarheid van individuele artikelen. Teun Lucassen voerde in dit kader een promotieonderzoek uit naar de vraag hoe gebruikers de betrouwbaarheid van online informatie beoordelen. Hij doet verslag van zijn bevindingen.
Teun Lucassen
Vandaag de dag is veel informatie voor iedereen online toegankelijk. De betrouwbaarheid van informatie is in vergelijking met vroeger onzekerder geworden en het inschatten ervan moeilijker. Veel eindgebruikers zijn hiervoor onvoldoende getraind. Daar komt nog bij dat de meest traditionele strategie voor het inschatten van betrouwbaarheid: het beoordelen van de bron van de informatie,1 niet meer goed werkt.
In veel gevallen is de bron onbekend. Soms zijn bronnen ‘gelaagd’:2 de informatie reist door meerdere lagen voordat het de gebruiker bereikt. Neem bijvoorbeeld een blogposting die gebaseerd is op een Wikipedia-artikel, waarbij het Wikipediastuk weer grotendeels onderbouwd wordt door een bericht op een nieuwswebsite. In dit soort gevallen is het lastig om te bepalen wie er verantwoordelijk is voor de betrouwbaarheid van de informatie.
Wikipedia
De problemen die internetgebruikers hebben met het inschatten van de betrouwbaarheid van online informatie, zijn onderzocht in verschillende disciplines. Diverse aspecten van vertrouwen in online informatie zijn daarbij al aan bod gekomen, zoals kenmerken van de informatie,3 de context4 en de gebruiker.5 Mijn promotieonderzoek gaat in op de vraag welke invloed de karakteristieken van de gebruiker hebben op de inschatting van betrouwbaarheid. Of anders gezegd: hoe gaan gebruikers met verschillende kenmerken om met de betrouwbaarheid van online informatie?
Om dit onderzoek te kunnen verrichten is er een context nodig waarin we het vertrouwen in informatie kunnen bestuderen. Wij hebben gekozen voor Wikipedia, een grote online encyclopedie die geheel door vrijwillige bijdragen van gebruikers tot stand komt. Wat deze website voor het onderzoek zo interessant maakt, is de ‘Wikipedia-paradox’. Aan de ene kant is bekend dat informatie op Wikipedia over het algemeen van hoge kwaliteit is.6 Aan de andere kant kun je er door de open structuur van Wikipedia nooit helemaal van op aan dat een gelezen artikel ook daadwerkelijk betrouwbaar is. Gebruikers moeten altijd zelf de betrouwbaarheid inschatten.
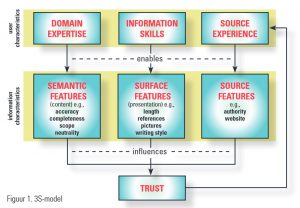
3S-model
Om te beginnen hebben we drie kenmerken van gebruikers geïdentificeerd die naar onze verwachting het oordeel over betrouwbaarheid beïnvloeden. Dit zijn:
- domeinexpertise (de mate waarin de gebruiker kennis heeft over het onderwerp),
- informatievaardigheden (hoe vaardig is de gebruiker in het omgaan met online informatie) en
- ervaring met de bron.
In een nieuw model, 3S genaamd (zie figuur 1), veronderstelden we dat deze drie eigenschappen respectievelijk zouden leiden tot het gebruik van:
- semantische kenmerken van de informatie (de eerste ‘S’ van het model, corresponderend met de inhoud van de informatie; denk daarbij aan de feitelijke correctheid of de neutraliteit);
- oppervlaktekenmerken (surface features, de tweede ‘S’, de manier waarop informatie gepresenteerd wordt, zoals de aanwezigheid van afbeeldingen, de lengte van een tekst of het aantal referenties);
- bronkenmerken (source features, de derde ‘S’; denk bijvoorbeeld aan de specifieke lay-out van Encyclopædia Brittanica versus die van Wikipedia). In een aantal experimenten hebben we deze veronderstellingen getest.
Expertise
In een online experiment lieten we experts én beginners op het gebied van autotechniek Wikipedia-artikelen over automotoren zien. De feitelijke juistheid van deze artikelen was op verschillende niveaus gemanipuleerd: in maximaal de helft van de artikelen zaten fouten.
De validiteit van het semantische deel van het 3S-model bleek uit het feit dat het vertrouwen van de experts werd beïnvloed door de fouten, het vertrouwen van de beginners niet. Maar de invloed op het vertrouwen van de experts was beperkt. Hieruit concludeerden we dat ook experts gebruik maken van oppervlakte- en bronkenmerken. Uit de opmerkingen van proefpersonen bleek dat zowel experts als beginners in meer of mindere mate gebruik maakten van alle strategieën uit het 3S-model.
Informatievaardigheden
Vervolgens hebben we gekeken naar de tweede karakteristiek: informatievaardigheden. We hebben scholieren, bachelorstudenten en promovendi Wikipedia-artikelen laten beoordelen door middel van hardop denken. We zijn ervan uitgegaan dat deze groepen behoorlijk verschillen in hun informatievaardigheden. De Wikipedia-artikelen werden op de persoon geselecteerd, om ervoor te zorgen dat de proefpersonen veel of juist weinig over het onderwerp wisten. De helft van de artikelen was van hoge kwaliteit en de andere helft van lage kwaliteit, volgens de beoordelingen van Wikipedia zelf. De hardop-denkprotocollen zijn geanalyseerd.
De resultaten kwamen overeen met de veronderstellingen in het 3S-model. Meer bekendheid met het onderwerp leidde inderdaad tot meer gebruik van semantische kenmerken, maar niet tot meer of minder vertrouwen. Bachelorstudenten en promovendi maakten meer gebruik van oppervlaktekenmerken dan scholieren. Scholieren bleken niet in staat om artikelen van hoge en lage kwaliteit van elkaar te onderscheiden, terwijl de andere twee groepen dat wel konden.
Referenties
Eén specifiek oppervlaktekenmerk bleek voor bachelorstudenten bijzonder belangrijk, namelijk de referenties. Reden om in een vervolgexperiment het belang hiervan nader te onderzoeken. In dit experiment werden de referenties van Wikipedia-artikelen in twee opzichten gemanipuleerd, namelijk in kwantiteit en in kwaliteit. De kwantiteit werd gemanipuleerd door het aantal referenties te variëren tussen ongeveer 5 en 25. De kwaliteit werd gemanipuleerd door alle referenties te verwisselen met die van een ander, niet-gerelateerd artikel.
De verwachting was dat de kwantiteitsmanipulatie meer op zou vallen dan de kwaliteitsmanipulatie, omdat er slechts een vlugge blik nodig is om dit te ontdekken (een zogenaamde heuristische evaluatie). De kwaliteitsmanipulatie daarentegen vereist veel meer aandacht om ontdekt te worden (een systematische evaluatie).
Uit het onderzoek bleek dat de proefpersonen beide evaluatiestrategieën (heuristisch en systematisch) toepasten. De keuze tussen de strategieën was afhankelijk van het vertrouwen in de bron. Personen met een sceptische houding ten opzichte van Wikipedia hadden de neiging om de informatie systematischer te evalueren, terwijl degenen met een minder kritische houding slechts een heuristische evaluatie uitvoerden.
Bovendien bleek ondanks de grote interesse voor referenties in eerdere experimenten slechts 26 procent van de proefpersonen de kwaliteitsmanipulatie opgemerkt te hebben. Voor de kwantiteitsmanipulatie lag dit percentage iets hoger (39 procent). We noemen dit fenomeen ‘referentieblindheid’. De aanwezigheid van referenties is belangrijk voor studenten, de kwantiteit en vooral de kwaliteit veel minder.
Bron van informatie
De derde ‘S’ van het 3S-model, oftewel ervaring met de bron (source), was het onderwerp van studie in het volgende experiment, samen met domeinexpertise. In zijn onderzoek uit 20017 opperde Matthew Eastin dat de bron van informatie minder belangrijk is voor het inschatten van betrouwbaarheid als de gebruiker bekend is met het onderwerp. In het experiment dat toentertijd uitgevoerd werd kon hiervoor echter geen ondersteuning worden gevonden.
Wij onderzochten deze relatie verder door proefpersonen Wikipedia-artikelen te tonen in de standaard Wikipedia-lay-out en in een gestandaardiseerde lay-out (gebaseerd op de standaard lay-out van Microsoft Word 2003).
In tegenstelling tot de originele hypothese van Eastin bleek het vertrouwen van proefpersonen die onbekend waren met het onderwerp, niet beïnvloed door de aanwezigheid van broneigenschappen. Proefpersonen die wel bekend waren met het onderwerp werden wel beïnvloed, maar alleen wanneer de kwaliteit van de artikelen bedenkelijk was. In dat geval hadden zij minder vertrouwen in de informatie wanneer ze wisten dat het van Wikipedia kwam.
Het verschil tussen onze resultaten en de hypothese van Eastin kan worden verklaard door het open karakter van Wikipedia. Mensen die bekend zijn met het onderwerp schatten hun eigen kennis wellicht hoger in dan dat van (onbekende) anderen.
Lagenmodel
3S-model zijn in een breder perspectief geplaatst in een nieuw model, waarbij in verschillende lagen de invloed van gebruikerskarakteristieken op vertrouwen in informatie wordt uitgelegd (zie figuur 2). De kern van dit lagenmodel is vertrouwen in de informatie zelf (gebaseerd op de evaluatie van semantische en oppervlaktekenmerken). De eerste laag hieromheen vertegenwoordigt vertrouwen in de bron van de informatie. De tweede laag is vertrouwen in het medium waarop de bron te vinden is (een generalisatie van vertrouwen in meerdere, vergelijkbare bronnen, zoals internet of kranten). De buitenste laag staat voor een algemene geneigdheid tot vertrouwen als karaktereigenschap.
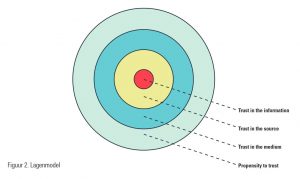
We veronderstelden dat iedere laag een directe invloed zou hebben op de aangrenzende laag. De invloed op verder weg gelegen lagen wordt gemedieerd door de tussenliggende laag of lagen. De resultaten van een online experiment ondersteunden alle voorgestelde relaties. Daarnaast liet een post-hoc analyse zien dat gebruikers met weinig vertrouwen in de bron (in dit geval Wikipedia) geen verschil zagen tussen artikelen van hoge en lage kwaliteit, terwijl gebruikers met meer vertrouwen in de bron dit wel zagen. Dit is een indicatie voor een negativiteitsbias voor wantrouwende gebruikers, maar geen positiviteitsbias voor vertrouwende gebruikers.
Ondersteuning
De modellen die in dit proefschrift zijn geïntroduceerd geven ons meer inzicht in de manier waarop internetgebruikers de betrouwbaarheid van informatie inschatten. Ze laten zien welke problemen er kunnen ontstaan bij het inschatten van de betrouwbaarheid. Denk bijvoorbeeld aan een tekort aan domeinexpertise, informatievaardigheden, motivatie of bekwaamheid. Een mogelijke oplossing voor deze problemen is om gebruikers te ondersteunen met een beslissingsondersteunend systeem. De toepassing en acceptatie van dergelijke systemen hebben we onderzocht in twee experimenten.
In het eerste experiment zijn drie gesimuleerde ondersteuningssystemen aangeboden. We hebben gebruikers gevraagd om een keuze te maken tussen ondersteuning gebaseerd op de meningen van eerdere gebruikers of een geautomatiseerd systeem. Had een geautomatiseerd systeem de voorkeur, dan was er nog de keuze tussen een complex (goede prestaties, maar moeilijker te begrijpen) of een simpel (minder goede prestaties, maar beter te begrijpen) systeem.
Voor wat betreft de eerste keuze konden geen eenduidige conclusies worden getrokken; beide systemen hebben voor- en nadelen. Vertrouwen in ondersteuning op basis van eerdere gebruikers is sterk afhankelijk van het aantal gebruikers en hun geloofwaardigheid. Daarentegen is geautomatiseerde ondersteuning gevoelig voor onterecht vertrouwen, omdat de betrouwbaarheid van het advies naar alle waarschijnlijkheid nooit honderd procent zal zijn in complexe dynamische omgevingen zoals internet. De simpele geautomatiseerde ondersteuning werd echter wel snel uitgesloten, omdat de proefpersonen de gehanteerde ondersteuningsprincipes te simplistisch vonden.
Experts en beginners
In het tweede experiment werd een directe link gelegd tussen het 3S-model en de toepassing van geautomatiseerde beslissingsondersteunende systemen. We hebben inmiddels gezien dat domeinexperts de betrouwbaarheid op een andere manier inschatten dan beginners; zij letten meer op semantische kenmerken van de informatie.
In dit experiment hebben we onderzocht of dit ook consequenties heeft voor de toepassing van geautomatiseerde beslissingsondersteunende systemen. Proefpersonen die al dan niet bekend waren met het onderwerp van de informatie, kregen twee verschillende ondersteuningssystemen aangeboden. Het eerste systeem baseerde het advies op semantische kenmerken, terwijl het tweede systeem zich baseerde op oppervlaktekenmerken.
Na beide systemen een paar keer uitgeprobeerd te hebben mochten de proefpersonen zelf kiezen welk systeem ze wilden gebruiken voor het laatste artikel in het experiment. Deze keuze werd gezien als een goede indicatie voor hun voorkeur. Proefpersonen die onbekend waren met het onderwerp kozen over het algemeen het systeem dat gebruik maakte van oppervlaktekenmerken, terwijl de proefpersonen die wel bekend waren met het onderwerp geen duidelijke voorkeur hadden. We concludeerden dat ontwikkelaars van dergelijke systemen zich het beste op gebruikers kunnen richten die onbekend zijn met het onderwerp. Gebruikers die wel bekend zijn met het onderwerp zijn zelf beter in staat om de betrouwbaarheid in te schatten en hebben daardoor minder behoefte aan ondersteuning.
Tot slot
Al met al kunnen we enkele conclusies trekken uit het onderzoek dat ik in het kader van mijn proefschrift heb verricht: > Het vertrouwen dat mensen stellen in informatie is aanvankelijk vooral gebaseerd op hun vertrouwen in de bron, dat weer gebaseerd is op vertrouwen in het medium en op een algemene geneigdheid tot vertrouwen.
- Gebruikers krijgen beter betrouwbare informatie als ze niet alleen afgaan op hun (passieve) vertrouwen in de bron maar ook actief de informatie die ze voor zich krijgen evalueren aan de hand van semantische en oppervlakte-eigenschappen.
- Karakteristieken van de gebruiker, zoals domeinexpertise, informatievaardigheden of vertrouwen in een bron, hebben een grote invloed op de manier waarop betrouwbaarheid wordt ingeschat.
- Het is essentieel om rekening te houden met gebruikerskarakteristieken in de ontwikkeling van beslissingsondersteunende systemen, bijvoorbeeld door advies te baseren op informatiekenmerken die de gebruiker zelf ook zou hanteren.
Noten
- Chaiken, S. & Maheswaran, D. (1994). Heuristic processing can bias systematic processing: Effects of source credibility, argument ambiguity, and task importance on attitude judgment. Journal of Personality and Social Psychology, 66, 460-473.
- Sundar, S. S. & Nass, C. (2001). Conceptualizing sources in online news. Journal of Communication, 51, 52-72.
- Kelton, K., Fleischmann, K. R., & Wallace, W. A. (2008). Trust in digital information. Journal of the American Society of Information Science and Technology, 59, 363-374.
- Metzger, M. J. (2007). Making sense of credibility on the Web: Models for evaluating online information and recommendations for future research. Journal of the American Society for Information Science and Technology, 58, 2078-2091.
- Fogg, B. J. (2003). Prominence-interpretation theory: Explaining how people assess credibility online. In ACM Conference on Human Factors in Computing Systems (CHI’03), extended abstracts, 722-723. New York, NY, USA: ACM Press.
- Giles, J. (2005). Internet encyclopaedias go head to head. Nature, 438, 900-901.
- Eastin, M. S. (2001). Credibility assessments of online health information: The effects of source expertise and knowledge of content. Journal of Computer-Mediated Communication, 6.
Teun Lucassen is op 1 maart 2013 gepromoveerd op zijn proefschrift ‘Trust in online information’. Zijn promotor was prof.dr. Jan Maarten Schraagen. Vanuit zijn interesse in het werken met studenten en het spanningsveld tussen mens en technologie is hij verder in het onderwijs gedoken; hij werkt nu als hogeschooldocent Serious Gaming aan de Hogeschool Windesheim in Zwolle.
Deze bijdrage komt uit IP nr. 4 / 2013. Het gehele nummer kun je hier lezen