De vijftien jaar dat InformatieProfessional bestaat, lopen bijna gelijk met de geschiedenis van webzoekmachines. Bijna, want de eerste bruikbare zoekmachines verschenen in 1994, drie jaar voor de eerste jaargang van het vakblad. Dat InformatieProfessional vanaf het begin veel aandacht heeft besteed aan de ontwikkelingen op dit terrein, is voor Eric Sieverts aanleiding om in het kader van het jubileum speciaal op die zoekmachines terug te kijken.
Door: Eric Sieverts
Het woord zoekmachines lijkt in Nederland nauwelijks meer in het meervoud gebruikt te kunnen worden, omdat Google hier een bijna-monopoliepositie heeft verworven, nog veel sterker dan in de VS zelf. Dat dat wel anders is geweest toont de lange rij namen in de tijdlijn bij dit artikel, namen waarvan een deel nog vage herinneringen oproept, maar waarvan er nog maar enkele als zelfstandige zoekmachines opereren.
Mijn eigen geschiedenis met zoekmachines begint in 1995, toen ik in Login, een van de twee ouders van InformatieProfessional, een bespreking wijdde aan Lycos, de eerste bruikbare zoekmachine voor het web. Onvoorstelbaar dat we toen zo opgewonden werden over een zoekmachine die 1,5 miljoen webpagina’s doorzoekbaar maakte. Mijn bespreking was de eerste bijdrage in een serie onder de kunstmatig allittererende titel ‘Wie weet welke wellicht waardevolle wijsheid waar op het web op ons wacht’. In InformatieProfessional werd die serie door Hans van der Laan en mij voortgezet, aanvankelijk onder de korte zakelijke serietitel WWW.WAAR.WAT, later verlengd tot WWW. WIE.WAAR.WAT met intussen veel bijdragen van Jeroen Bosman.
Wie was de grootste?
In de beginjaren van de zoekmachines speelde hun grootte een belangrijke rol. Wie had het grootste deel van het web weten te indexeren? Op de website van SearchEngineWatch (SEW) werd de grootte van de belangrijkste webzoekmachines regelmatig in staafdiagrammen bijgehouden. Meestal waren die cijfers afkomstig van de bedrijven zelf, die daar toen nog niet geheimzinnig over deden.
Ook waren bij SEW al gauw grafieken te vinden waarin het verloop van die grootte door de jaren heen was af te lezen. Daarin namen de verschillende zoekmachines regelmatig de koppositie van elkaar over. In die beginjaren placht ik tijdens zoekcursussen te waarschuwen dat wat je met die mooie zoekmachines op het web kon vinden, veel en veel minder was dan wat bij grote online hosts als Dialog of LexisNexis beschikbaar was. Zelfs toen in 1998 de omvang van AltaVista al 100x zo groot was geworden als die eerste 1,5 miljoen pagina’s van Lycos uit 1995, zat er nog een factor 20 verschil tussen – in het voordeel van de professionele databaseaanbieders welteverstaan. Dat was ook de tijd waarin – in de eerste jaargang van InformatieProfessional – een artikel verscheen waarin werd aangetoond dat informatievragen met behulp van de gedrukte OB-collectie sneller beantwoord konden worden dan door op internet te zoeken. De meeste informatie was daar nog helemaal niet beschikbaar.
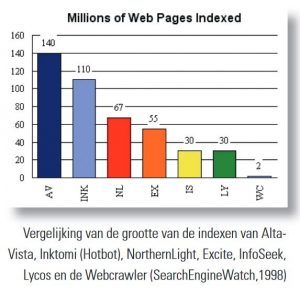
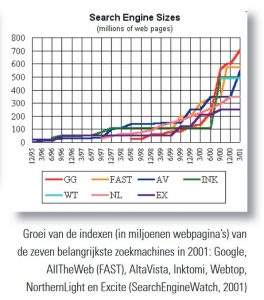
Maar die tijden zijn voorbij. Een verdubbeling elk jaar vormt een aardige illustratie van het verschijnsel exponentiële groei. In minder dan vijf jaar is zo’n factor 20 weggewerkt. En nog eens vijf jaar verder (rond 2007) was de situatie precies omgekeerd en boden de grote webzoekmachines toegang tot 20x zoveel items als die oude hostorganisaties.
Steeds groter
Een verdubbeling elk jaar, waar komt dat cijfer vandaan? In de eerste plaats inderdaad uit gegevens van SEW. In de loop van de tijd kwam daar echter steeds meer discussie over het nut de groottes van zoekmachines te achterhalen. De meeste stopten zelf namelijk met het vermelden van hun omvang; voor hen was het geen marketingargument meer. Men zette nu in op relevantie-ordening: als die maar goed was, hinderde het niet als je minder had dan de concurrent. Dat idee werd ook door SEW overgenomen. Zelf heb ik dat altijd onzinnig gevonden, want als een zoekmachine de beste resultaten voor een vraag niet in zijn index heeft zitten, heb je ook niets aan zijn sublieme relevantievolgorde.
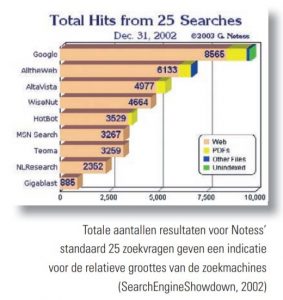
In die tijd ben ik zelf toen maar wat vergelijkingen gaan uitvoeren. Mijn methode was geïnspireerd op de wijze waarop Greg Notess de groottes van zoekmachines vergeleek, op zijn website SearchEngineShowdown. Hij liet op regelmatige tijden een aantal standaard zoekvragen op alle onderzochte zoekmachines los, telde de aantallen resultaten per zoekmachine bij elkaar op en gebruikte die getallen – statistisch misschien niet helemaal waterdicht – als indicatie voor hun relatieve grootte.
Zelf probeerde ik mijn cijfers te relateren aan de laatste nog wel gerapporteerde groottes van die zoekmachines. Mijn simpele redenering: als Google op mijn vragen nu tweemaal zoveel oplevert als acht maanden geleden, dan zal het aantal webpagina’s in de hele index ook wel verdubbeld zijn. Ook in InformatieProfessional heb ik in die tijd (2004) wat vergelijkende resultaten tussen een flink aantal zoekmachines gerapporteerd. In het grafiekje hieronder zijn al die cijfers – eerst van SEW, later uit mijn berekeningen – op een logaritmische schaal uitgezet. Dat geeft een mooie rechte lijn, een bewijs van echte exponentiële groei. Bijna 15 jaar lang was de omvang van de grootste zoekmachine van dat moment gemiddeld elk jaar vrijwel verdubbeld. Een factor 10.000 in 14 jaar – en als we die allereerste Lycos-index ook meetellen, zelfs een factor 100.000.
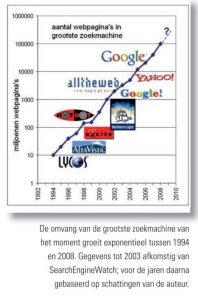
Hoe groot nu?
Maar waarom stopt die grafiek ineens in 2008? Daar is een aantal redenen voor:
- Ervaring leerde dat de aantallen resultaten die zoekmachines (en in het bijzonder Google) opgaven te hebben gevonden, steeds onbetrouwbaarder werden, zodat vergelijking met eerdere aantallen eigenlijk niet goed meer mogelijk was.
- Zoekmachines doen telkens andere dingen met de woorden uit je zoekvraag waardoor het steeds moeilijker wordt een zoekmachine te dwingen echt dezelfde zoekvraag uit te voeren. Vergelijking met eerdere aantallen is ook om die reden niet goed meer mogelijk.
- Het wordt steeds moeilijker te definiëren wat als afzonderlijke webpagina’s of webdocumenten geteld moet worden. Is elke tweet een webpagina? Heb je te maken met een andere pagina als automatisch een iets ander sessienummer in een url wordt verwerkt en een van de 20 blokjes informatie op de pagina verschilt? Zijn gepersonaliseerde pagina’s die verschillende gebruikers op dezelfde site te zien krijgen, verschillende pagina’s?
- De ‘dingen’ die je op internet vindt zijn steeds minder vergelijkbaar. Tellen de miljarden tweets van 140 tekens even zwaar mee als pdf’s van 140 pagina’s als je groottes vergelijkt?
Verbetering van zoekvragen
Webzoekmachines hebben een heel nieuwe manier van zoeken geïntroduceerd, doordat ze aan de gebruikerskant heel anders werkten dan de zoeksystemen waaraan informatiespecialisten tot dan toe gewend waren. Vooral het best-match zoeken, dat gebruik van AND-operatoren overbodig maakte, betekende een grote verandering. Maar daar bleef het niet bij; hulp bij het verbeteren van zoekvragen heeft het vinden van relevante informatie ook meer binnen het bereik van niet-professionals gebracht.
Al in 1998 kwam een aantal zoekmachines na elke zoekvraag met een rijtje potentiële zoektermen die met de zoekvraag samenhingen – soms simpel zoals bij Excite, InfoSeek en Euroferret, soms heel geavanceerd, zoals bij AltaVista. Dergelijke op basis van woordstatistiek gegenereerde termen waren meestal bedoeld om zoekresultaten in te perken, simpelweg door een relevante term aan te vinken of aan te klikken. Overigens was die functionaliteit niet echt nieuw, want online hosts als ESA en Dialog deden anno 1985 al net zoiets, met hun ZOOM- of RANK-commando’s. Na een paar jaar verdween die mooie functionaliteit veelal weer geruisloos, of omdat die niet gebruikt werd, of omdat de betreffende zoekmachines verdwenen. Later kwamen nieuwe zoekmachines wel weer met verbeterde versies, zoals Teoma, en Wisenut en nog wat later het Russische Quintura dat enige tijd als front-end op Yahoo fungeerde.

De grote zoekmachines zelf – Google voorop – begonnen geleidelijk suggesties te tonen die al tijdens het intikken van de zoekvraag gegenereerd werden. Maar die waren vooral gebaseerd op de veelheid aan eerder gestelde vragen waaruit zij konden putten. Bij Google culmineerde dat in het al tonen van wellicht bedoelde resultaten terwijl de vraag nog wordt ingetikt – Google Instant.
Zoekmachines weten het beter
Waar deze technieken vooral voor het verfijnen van de vraag waren bedoeld, introduceerde Google de laatste paar jaar eveneens technieken die de opbrengst van zoekvragen, de recall, ten goede moesten komen. Dat begon al met suggesties voor anders (en dus correcter?) gespelde woorden die meer zouden opleveren. Meer geavanceerd was echter het automatisch toevoegen van enkel- en meervoud, andere woordvarianten en samengestelde woorden – zogenaamde lemmatization – en geleidelijk ook meer synoniemen van de oorspronkelijke zoekwoorden.
Het automatisch zoeken op iets anders dan je als zoekvraag hebt ingetikt, omdat de zoekmachine denkt beter te weten wat je bedoelt, wordt door professionele zoekers steeds meer verafschuwd. De Britse zoekexpert Phil Bradley bracht dat in zijn blog al tot de uitroep: ‘No Google, I know best’. Dat Google uiteindelijk een aparte optie ‘Verbatim’ introduceerde om toch weer ‘woordelijk’ te kunnen zoeken, hangt wellicht samen met die sterk gegroeide onvrede.
15 years from now?
Hoewel vijftien jaar maar kortgeleden lijkt, is in die tijd zoveel veranderd, dat vijftien jaar in de toekomst kijken een onzalige gedachte lijkt. Hooguit kunnen we kijken of we verwachten dat al eerder ingezette trends doorzetten en wat die voor informatieprofessionals betekenen.
Een van die trends is dat zoekmachines beweren meer erop uit te zijn antwoorden te geven, dan lijstjes documenten te produceren. Bing afficheerde zich bij zijn introductie als een ‘decision engine’ en ook Google probeert meer op feitelijkheden in te zetten. Een systeem dat echt alleen antwoorden probeert te geven is natuurlijk Wolfram|Alpha. Toch is ook dat niet echt nieuw. Al in 1996 werd AskJeeves opgericht, dat op wat minder pretentieuze wijze datzelfde doel nastreefde.
Een andere trend is die van de semantiek. Er komen steeds meer semantisch gecodeerde gegevens beschikbaar, zowel als linked open data, als in de vorm van metadata die volgens diverse standaarden in de codering van webpagina’s worden verwerkt. Semantische zoekmachines die ‘begrijpen’ wat in gevonden documenten wordt bedoeld, maar dan ook moeten begrijpen wat wij met onze zoekvragen bedoelen, zouden daarmee geleidelijk tot de mogelijkheden moeten gaan behoren. Een derde ook al niet eens meer heel recente trend is die van de sociale media, waar antwoorden meer door voorkeuren van onze (virtuele) sociale omgeving worden bepaald, dan dat ze van zoekmachines komen.
Gezamenlijk kenmerk van al deze ontwikkelingen is dat daarbij autonoom, zonder te vragen, een heleboel met onze zoekopdrachten wordt gedaan. Of dat is wat informatieprofessionals appreciëren is de vraag, gezien de reacties op Googles eigenmachtige zoekgedrag. Maar dergelijke systemen zijn natuurlijk ook al helemaal niet meer voor ons soort professionals bedoeld. Een vervolgvraag is dan ook of die systemen zo goed worden dat ‘zoeken en vinden’ helemaal niet meer tot de taken van de informatieprofessional zal gaan behoren.
Kleine geschiedenis van de webzoekmachine; een tijdlijn
1994
Lycos en Webcrawler zijn de eerste enigszins volwassen zoekmachines voor het web.
Vooral Lycos, ontwikkeld aan Carnegie Mellon University, zet de toon, al bevat zijn index pas 1,5 miljoen webpagina’s. Toepassing van best-match zoeken wordt de algemene standaard: tik wat woorden in en je krijgt eerst die pagina’s – als meest relevante – waarin de meeste, maar niet noodzakelijkerwijs alle zoekwoorden voorkomen.
1995
NlightN, WWW Worm en Yahoo komen erbij. Yahoo doorzoekt nog alleen de sites in zijn gelijknamige onderwerpsgids (de Yahoo!-directory). Er zijn zo’n 10 miljoen webpagina’s doorzoekbaar. Op 15 december wordt AltaVista gelanceerd. Deze door Digital Equipment ontwikkelde zoekmachine wordt de nieuwe standaard voor zoeken op het web.
1996
AltaVista krijgt concurrentie van InfoSeek, Hotbot, Excite en OpenText. Hotbot is gebaseerd op de index van Inktomi, een bij Berkeley University ontwikkelde zoekmachine die vooral resultaten voor andere zoekdiensten levert. OpenText dient vooral als reclame voor het softwareproduct dat voor enterprise search op de markt wordt gebracht. Er zijn zo’n 50 miljoen webpagina’s doorzoekbaar.
1997
Nieuwe zoekmachines zijn NorthernLight en MSN. Die laatste, van Microsoft, is ook gebaseerd op de Inktomiindex. NorthernLight combineert het gewone zoeken met een automatische categorie indeling. Pagina’s worden daartoe op basis van kennisregels op onderwerp ingedeeld. Enkele jaren later vinden we NorthernLight alleen nog als leverancier van enterprisesearchsoftware. Er verschijnen ook regionale zoekmachines, zoals Euroferret (Europese sites, op basis van Muscat retrieval software) en Ilse (Nederlandse sites).
Er zijn ruim 100 miljoen webpagina’s doorzoekbaar.
1998
Zoekmachines veranderen hun standaard best-match zoekalgoritme van ‘most of the terms’ in ‘all of the terms’. Er zijn toch altijd al te veel resultaten waarin de ingetikte zoektermen allemaal voorkomen. Andere factoren dan het aantal aanwezige zoektermen spelen dus de belangrijkste rol bij de relevantie-ordening. Excite, Infoseek en Euroferret geven suggesties voor alternatieve zoektermen. Die worden op basis van woordstatistiek uit het al verkregen zoekresultaat afgeleid. Ze zijn vooral bedoeld om zoekacties daarmee in te perken. AltaVista doet dat nog geavanceerder, door termen te clusteren in groepen die in dezelfde context voorkomen. In een grafische presentatie kunnen de termen individueel in een AND- of NOT-relatie worden toegevoegd. Dat interface wordt zo ingewikkeld gevonden dat de optie na een jaar helaas al weer verdwijnt.
1999
Opkomst van de nieuwe grote zoekmachines Google en Alltheweb (van het Noorse bedrijf FAST) die een betere relevantieordening bieden, onder meer gebaseerd op de mate waarin naar webpagina’s gelinkt wordt. De oudere zoekmachines zoals Infoseek, NorthernLight, AltaVista, Excite en Ilse raken daardoor in de problemen. AltaVista raakt bovendien in opspraak, doordat het laat betalen voor een betere ranking. Door de vele negatieve reacties wordt het ijlings teruggedraaid, maar het kwaad is al geschied. Andere zoekmachine hebben van deze dure les geleerd.
Een VOGIN-werkgroep doet een gecontroleerde test naar de reproduceerbaarheid van de grote zoekmachines. Omdat zoekprofessionals toen nog niet verwachtten dat zoekmachines inconsequent en onreproduceerbaar zouden kunnen zijn, werden de negatieve uitkomsten in InformatieProfessional breed uitgemeten.
Er zijn zo’n 200 miljoen webpagina’s doorzoekbaar.
2000
Webtop schaart zich bij de grote zoekmachines. Het dient ter demonstratie van de commercieel verkrijgbare Muscat-retrievalsoftware. Daardoor hebben updates wat minder prioriteit, zodat hij weinig populair wordt.
2001
De zoekmachineserie van InformatieProfessional schenkt eindelijk uitgebreid aandacht aan Google dat dat jaar een Webby-award heeft gekregen. Google is de eerste die ook andere soorten documenten dan webpagina’s begint te indexeren, zoals pdf’s en Word-documenten. Andere zoekmachines (en andere documentformaten) zullen spoedig volgen. Google indexeert intussen meer dan 1 miljard webpagina’s.
Teoma en Wisenut zijn twee nieuw komers. Teoma heeft een nog slimmere methode dan Google om relevantievolgorde uit link-populariteit te berekenen. Beide groeperen hun zoekresultaten op onderwerp. Die context wordt bepaald door statistische woordanalyse.
2002
Gigablast en Exalead zijn twee nieuwe zoekmachines met elk unieke functionaliteit. Teoma past zijn presentatie aan, waardoor zoekresultaten makkelijker op de juiste context kunnen worden ingeperkt door aanklikken van door het systeem gesuggereerde woorden of uitdrukkingen. Als antwoord op een zoekvraag toont het apart een rijtje websites met het karakter van een onderwerpsgids. Omdat Google al zo de ‘standaard’ is geworden, wordt in de zoekmachineserie van InformatieProfessional maar eens breed uitgemeten wat anderen beter kunnen. Ook wordt het grote ‘uitsterven’ aangekondigd: Infoseek, Excite, NorthernLight en Webtop hebben het als gewone webzoekmachine opgegeven.
2003
Hoewel het met AltaVista weer beter gaat en Alltheweb moeite doet de grootste te worden, heeft Google toch definitief de positie van belangrijkste zoekmachine veroverd. Yahoo biedt ook een grote zoekmachine, maar maakt daarvoor gebruik van de Google-index.
2004
Omdat Yahoo op eigen benen wil staan, neemt het zowel Inktomi, als AltaVista, als Alltheweb over. Hun gezamenlijke content resulteert in een zeer grote Yahoo-index, maar in AltaVista en Alltheweb zelf blijkt weinig van de oorspronkelijke inhoud te zijn over gebleven. Later in het jaar komt die inhoud geleidelijk weer terug.
Ook Google neemt steeds meer andere bedrijven over en beleeft een succesvolle beursgang. Microsoft mengt zich eindelijk zelfstandig in de concurrentieslag met een eigen MSNsearch bèta, later MSN Live genoemd. Er kan intussen in 4 à 5 miljard webdocumenten gezocht worden. Wisenut (intussen overgenomen door Looksmart) en Teoma blijven interessante runners-up met elk meer dan 1 miljard webdocumenten.
2005
Ook Amazon mengt zich in de zoekmachinestrijd met A9, maar dat wordt geen succes. Google en Yahoo blijven de toon aangeven. Ondertussen hebben ze ook meer dan 20 aparte gespecialiseerde zoeksystemen onder zich, voor allerlei media en informatiesoorten. De ‘kleintjes’ Gigablast en Exalead groeien ook gestaag door naar 2 miljard webdocumenten.
2006
Door web 2.0-diensten met user generated content en recommendatie lijkt het echte zoeken wat op de achtergrond te raken.
Teoma, al eerder overgenomen door Ask.com, heet nu ook officieel Ask, maar raakt een deel van zijn aantrekkelijke functionaliteit kwijt. Microsoft lanceert definitief zijn eigen Live-zoekmachine.
Google lanceert zijn Custom Search Engine, waarmee ieder zijn eigen zoekmachine kan configureren. Voor de eerste paar talen wordt vertaald zoeken geïntroduceerd.
2007
Wikipediaoprichter Jimmy Wales komt met veel fanfare met een eigen zoekmachine Wikia, die echter geen succes wordt en weer geruisloos verdwijnt. De semantische zoekmachine Hakia wordt ook geen Google-killer, al bestaat die nog wel.
2008
Google voert ‘universal search’ in, waarbij het ook resultaten uit zijn andere zoeksystemen (plaatjes, video’s, nieuws, wetenschap, …) in gewone zoekresultaten verwerkt. Er worden meer dan 100 miljard webdocumenten doorzocht.
2009
Met veel marketinggeweld introduceert Microsoft zijn nieuwe zoekmachine Bing. Toch groeit het marktaandeel van Bing na een aanvankelijk piekje niet erg. Google introduceert een soort facetzoeken, waarmee de verschillende materialen uit de universal search weer uitgesplitst kunnen worden.
Met de komst van Twitter en Facebook (en eerder al weblogs) komt er steeds meer belangstelling voor zoeken in het realtime web. De grote zoekmachines pikken dat niet erg consequent en weinig succesvol op.
2010
Yahoo wordt overgenomen door Bing en gebruikt geen eigen index meer.
Google introduceert instant search. Het probeert te raden welke zoekvraag je aan het intikken bent en toont daar vast resultaten bij. Google doet ook eerste experimenten met semantische toepassingen. Bij recepten kun je onder andere op ingrediënten inperken. Zoekresultaten worden steeds sterker gepersonaliseerd. Er verschijnen toch weer twee nieuwe zoekmachines: Blekko en DuckDuckGo.
2011
Google probeert concurrentie met Facebook en Twitter aan te gaan met Google+. Intussen maakt het een puinhoop van zijn interface. Er worden ongevraagd steeds meer variaties aangebracht in je oorspronkelijke zoekvraag. Maar de optie om met + toch exact te zoeken verdwijnt juist. Na veel klachten komt daar een ‘Verbatim’-functie voor terug. Intussen worden geavanceerd zoeken, vertaald zoeken en allerlei andere Google-zoeksystemen steeds moeilijker te vinden.
Na 18 jaar bestaat Lycos nog altijd als bedrijf en als url, maar zijn inhoud en zijn functionaliteit betrekt het al jarenlang van anderen. Teoma blijkt onder die naam wel nog stiekem een eigen zoekmachine aan te bieden, al was het 5 jaar geleden in Ask opgegaan.
Zoeken of bladeren
Oude nummers van InformatieProfessional doorbladerend is het interessant de slingerbeweging te zien tussen de populariteit van zoeken en die van bladeren. Na het aanvankelijke enthousiasme over zoekmachines, ontstond rond 1998 geleidelijk onvrede over de verkregen zoekresultaten.
De populariteit van onderwerpsgidsen als de Yahoo! Directory en de OpenDirectory – en in Nederland Startpagina – nam daardoor sterk toe. Ook toen dankzij Google het zoeken weer populair werd, bleef de OpenDirectory op veel zoekwebsites beschikbaar. Teoma leverde als antwoord op zoekvragen apart ook een lijstje met relevante onderwerpsgidsen.
Toch was dat maar tijdelijk. Bij Teoma verdwenen de extra lijstjes, de OpenDirectory was op steeds minder sites beschikbaar en waar hij nog was, werd hij steeds minder gebruikt. Veel gespecialiseerde onderwerpsgidsen blijken al jaren niet meer geüpdatet. Toch lijkt er juist nu weer een kentering. Enerzijds zoeken we niet meer, maar laten we ons door onze sociale netwerken adviseren wat interessant is. Anderzijds is ‘content curation’ ineens een buzzword geworden en dat is eigenlijk een nieuw jasje voor het oude selecteren en beschikbaar stellen van informatie.
Gebruikers van zoekmachines
Enkele gegevens uit PEW Internet study of Search Engine Use 2012: Users are more satisfied than ever with the quality of search results. Search Engine Users Dislike Personalized Search But Like the Results.
- 91% find what they want most of the tim
- 73% think it’s trustworthy
- 55% think quality is getting better
- 65% see personalization as a bad thing
- 73% don’t want information collected on them even it if will improve search results.
Bron: http://pewinternet.org/Reports/2012/Search-Engine-Use-2012.aspx
Eric Sieverts is redacteur van InformatieProfessional.
Deze bijdrage komt uit IP nr. 5 / 2012. Het gehele nummer kun je hier lezen