In de vorige IP stond een bijdrage over het tegengaan van linkrot in digitaalerfgoedcollecties met behulp van persistent identifiers (IP 4/2016). Herbert Van de Sompel, die in het nummer daarvoor uitgebreid aan het woord kwam over technische oplossingen voor webarchivering (IP 3/2016), schreef op verzoek van IP een korte reactie. Hij gaat in op verschillende manieren om persistent identifiers technisch te implementeren en de noodzaak mensen ertoe te bewegen ook daadwerkelijk de juiste identifiers te gebruiken.
Door: Herbert Van de Sompel
De bijdrage van Maayke Rusken illustreert op een uitmuntende manier de behoefte aan stabiele identificatie voor digitale erfgoedcollecties. Als je op lange termijn betrouwbare toegang wilt bieden tot digitale objecten, en vooral als je de objecten van een bepaalde instelling wilt gaan incorporeren in een bredere, lokale, regionale of internationale context, dan is een stabiele manier om die objecten te kunnen identificeren en ernaar te kunnen verwijzen essentieel.
In deze bijdrage wil ik een aantal, vooral technische, toelichtingen geven op diverse aanpakken die er zijn om de beoogde persistentie te bereiken. En ik wil ook toelichten dat die oplossingen magisch noch gratis zijn.
Stabiliteit
In het algemeen kun je stellen dat een persistent identifier een webidentiteit geeft aan een object, en dat die identiteit middels speciale infrastructuur door de tijd stabiel gehouden wordt. Die stabiliteit is nodig omdat een object kan verhuizen van het ene webadres naar het andere. Dit kan zijn omdat er een platformmigratie plaatsvindt (de locatie-URI verandert binnen hetzelfde webdomein) of omdat een object overgaat naar een andere beheerder (de locatie-URI verandert naar een ander webdomein). Daarom wordt in persistent identifier-oplossingen de webidentiteit losgekoppeld van de weblocatie. Je hebt dus twee HTTP URI’s voor een object: eentje – de persistente HTTP URI – die de identiteit van het object aangeeft, en een andere – de locatie HTTP URI – die de locatie op het web aangeeft. Wanneer je de persistente HTTP URI aanklikt word je doorgestuurd naar de locatie-URI van het object.
Aanpak 1 en 2
Er zijn twee typische manieren om dit stramien te implementeren. De eerste, en bekendste, is gebaseerd op een gezamenlijke infrastructuur die over verschillende webdomeinen gebruikt kan worden. In dit geval worden de persistente URI’s aangemaakt in een gereserveerd webdomein. Wanneer je die URI’s aanklikt, word je doorgestuurd naar de locatie-URI’s die zich in verschillende domeinen kunnen bevinden. Voorbeelden van deze aanpak zijn onder meer DOI (Digital Object Identifier), handle, identifiers.org, PURL (Persistent Uniform Resource Locator) en W3ID. In deze aanpak wordt de correspondentie tussen de persistente URI en de locatie-URI bewaard in een tabel die up-to-date gehouden wordt door de beheerders van de respectievelijke objecten.
In een tweede aanpak maak je de persistente HTTP URI gewoon aan in hetzelfde domein van de locatie-URI en wordt de correspondentie lokaal beheerd; soms in een tabel, soms door gebruik te maken van simpele correspondentieregels die in de webserver worden ingebakken. Deze aanpak wordt bijvoorbeeld gebruikt door sommige institutional repository-platforms zoals eprints.org.
Niet gratis
Voor beide aanpakken geldt dat het bereiken van persistentie niet gratis is. Voor de eerste moet de gezamenlijke infrastructuur degelijk worden beheerd. Dat dit niet vanzelf gaat werd duidelijk toen in januari 2015 de DOI-infrastructuur tijdelijk onderuitging (tinyurl.com/zu4beac) omdat men vergeten was het domein doi.org te vernieuwen.
Voor allebei geldt ook dat je de correspondentie tussen persistente URI en locatieURI up-to-date dient te houden. En dat is niet zonder meer vanzelfsprekend. Recentelijk nog liet ik CrossRef – de belangrijkste speler in DOIs – weten dat verschillende DOIs gebruikt door de wetenschappelijke digitale bibliotheek JSTOR het niet meer deden. Het is een anekdote, maar wel eentje die erop wijst dat zelfs elegante en goedbedoelde infrastructuur onderhevig is aan menselijk falen.
Probleem
Een ernstig, en zelden besproken, probleem is dat de webinfrastructuur geen ingebouwde ondersteuning heeft voor persistente HTTP URI’s. Nadat je op de persistente URI hebt geklikt kom je bij de locatie-URI terecht. En als je het object dan bij je bladwijzers wilt stoppen of in een citatiemanager wilt opslaan, is het spijtig genoeg de locatie-URI die wordt opgeslagen. Daarom vertelt de op de locatieURI gepresenteerde pagina je vaak dat je dit object moet opslaan onder een andere URI, namelijk de persistente. Wat gebruikers uiteraard niet doen.
Dit probleem is allesbehalve een lachertje. In een recente studie (arxiv.org/abs/1602.09102) keken we naar 1,6 miljoen HTTP URI’s waarnaar in wetenschappelijke artikelen werd verwezen. We vonden dat zowat 700.000 URI’s refereerden naar webpagina’s en de overige 900.000 naar andere wetenschappelijke artikelen. Van die 900.000 was het merendeel – 500.000 – niet geciteerd met de persistente URI – de HTTP DOI – maar met de locatie-URI van de landing page. Doordat het web geen echte ondersteuning heeft voor persistente URI’s wordt de persistentie die met het gebruik van DOIs wordt beoogd niet bereikt. Dit irriteert me mateloos.
Daarom ik heb een projectje opgezet om dat te gaan veranderen, namelijk door een speciale link te gaan gebruiken in HTTP response headers die van de locatie-URI naar de persistente URI wijst. Als die link er is, dan zou je browser of citatiemanager de persistente URI eenvoudig kunnen opslaan.
Aanpak 3
Er is ook nog een derde aanpak om persistentie te bereiken voor URI’s: zonder gebruik te maken van speciale infrastructuur. Die bestaat erin gewoon vast te houden aan een webdomein – vergeet niet te betalen – en de URI’s in dat domein stabiel te houden. De aandachtige lezer van de bijdrage van Maayke Rusken zal de verwijzing naar het voortreffelijke linked data-werk van de Koninklijke Bibliotheek niet ontgaan zijn. De URI’s gebruikt in de KB-thesaurus voor auteursnamen hebben de vorm data.kb.nl/thesaurus/265748240. Niks persistent identifiers. De oplossing bestaat simpelweg uit URI’s en de intentie van de KB om te blijven bestaan en de URI’s stabiel te houden.
DOIs
Wetenschappelijke artikelen verwijzen naar andere wetenschappelijke artikelen. Om die referenties stabiel te houden werden midden jaren negentig DOIs (Digital Object Identifiers) ingevoerd. De bedoeling is dat naar artikelen wordt verwezen met de persistente HTTP DOI’s.
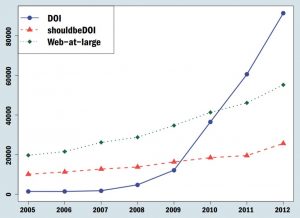
Spijtig genoeg is dit veelal niet het geval. Voor artikelen op de preprintserver arXiv (voornamelijk natuurwetenschappen en wiskunde/statistiek) is te zien dat het aantal DOI-referenties gestaag groeit vanaf 2009 (blauwe lijn, ‘DOI’). Maar ook referenties die gebruikmaken van de locatie-URI in plaats van de persistente HTTP DOI zitten in de lift (rode lijn, ‘ShouldBeDOI’). Voor artikelen in PubMedCentral (PMC), een repository voor de (bio)medische wetenschappen, is het beeld nog minder positief. Merk ook op dat het aantal verwijzingen naar pagina’s die geen wetenschappelijke artikelen zijn (groene lijn, ‘Web-at-large’) gestaag groeit.
DOIs bieden geen oplossing om die referenties persistent te houden. Dat doet de Robust Links-oplossing wel (zie het interview met Van de Sompel in nummer 3 van deze jaargang).
Herbert Van de Sompel, Martin Klein, and Shawn M. Jones. 2016. ‘Persistent URIs Must Be Used To Be Persistent’. In Proceedings of the 25th International Conference Companion on World Wide Web (WWW ‘16 Companion). arxiv.org/abs/1602.09102.
Herbert Van de Sompel is team leader van het Prototyping Team bij de Research Library van de Los Alamos National Laboratory
Deze bijdrage komt uit IP nr. 5 / 2016. Het gehele nummer kun je hier lezen.