Bibliotheekcollecties vormen meer en meer een onderdeel van een groter, mondiaal netwerk van digitale informatiebronnen, waarbij grenzen vervagen en informatie van velerlei aard en uit meerdere disciplines verbonden wordt. In dit artikel wordt voorgesteld actief aan deze ontwikkeling bij te dragen door het maken van een grote ommezwaai: één thesaurus voor alles. En niet een nieuwe, maar één die er al is, namelijk Wikidata.
Door: Theo van Veen
Zou het voor een gebruiker niet mooi zijn als hem, wanneer hij in een catalogus als zoekopdracht intypt ‘romeinse keizer’, de mogelijkheid geboden wordt op alle romeinse keizers te zoeken, in plaats van alleen op het tekstfragment ‘romeinse keizer’? En zou het voor de aanbieder van een dergelijke catalogus niet mooi zijn als dat ook heel makkelijk gerealiseerd kan worden?
Met linked data kunnen ‘dingen’ gekoppeld worden aan gerelateerde informatie en kunnen gebruikers die gerelateerde informatie opvragen en tussen gekoppelde informatie navigeren. Een auteur in een titelbeschrijving heeft bijvoorbeeld een link naar de thesaurus en de thesaurus heeft weer een link naar VIAF (Virtual International Authority File), enzovoort.
Willen gebruikers informatie uit verschillende bronnen combineren, dan moeten er dus koppelingen gelegd zijn tussen de identifiers uit die verschillende bronnen. Voor een deel ligt de noodzaak voor al die koppelingen in het ontbreken van een overkoepelende identifier voor elk ‘ding’. Een persoon kan in verschillende databases een verschillende identifier hebben die gebruikt wordt voor het leggen van verbindingen. In de Nederlandse gemeenschappelijk catalogus bijvoorbeeld is dat het zogenaamde PPN (Pica Productie Nummer). Maar wereldwijd wordt ook gebruik gemaakt van de identifiers in VIAF, in de wereldwijde catalogus van researchers (ISNI) et cetera. Nu meer en meer databronnen aan elkaar gelinkt worden, ligt het voor de hand te kijken naar de mogelijkheid en wenselijkheid van het terugbrengen van de veelheid van identifiers.
Eén centrale bron die al die identifiers verbindt, is al handiger dan een netwerk van bronnen en als er zo’n centrale bron is, kunnen we ons afvragen waarom we in lokale systemen ook niet zo veel mogelijk de identifiers van die centrale bron gaan gebruiken. Waarom? Omdat zoeken op één identifier een stuk eenvoudiger te realiseren is dan het koppelen van al die identifiers. In dit artikel wil ik aannemelijk maken dat, als dat handig is, het mogelijk vanzelf deze richting opgaat. Met een paar goede praktijkvoorbeelden zullen andere partijen waarschijnlijk al snel het gemak zien en zeggen: ‘Laten wij dat ook zo doen’.
Achtergrond
Bij de onderzoeksafdeling van de Koninklijke Bibliotheek (KB) wordt sinds enige tijd gewerkt aan het verrijken van krantenartikelen. Deze verrijkingen kunnen van velerlei aard zijn: geolocaties, links naar gerelateerde informatie, geëxtraheerde kenmerken, et cetera. Een belangrijk type verrijking wordt gevormd door ‘gelinkte named entities’. Dit zijn automatisch geëxtraheerde namen van personen, locaties en organisaties in een tekst die gelinkt zijn aan de overeenkomstige beschrijvingen in thesauri of internetencyclopedieën als DBpedia en Wikidata (beide linked open data-kennisbanken gebaseerd op Wikipedia) en VIAF. Het doel van het linken van named entities is meerledig:
- het eenduidig kunnen identificeren van namen in de tekst en daarmee het gericht kunnen zoeken van gedisambigueerde namen (de ene A. Einstein is gelinkt aan Albert Einstein, de andere aan Alfred Einstein), ongeacht de schrijfwijze (denk aan de vele naamsvarianten voor Tsjechov);
- het kunnen presenteren van contextinformatie bij een naam;
- het kunnen zoeken van objecten op basis van (semantische) kenmerken uit gelinkte bronnen.
Om deze doelen te realiseren, is in de researchomgeving van de KB begonnen met het verzamelen van de verschillende identifiers, zoals DBpedia, Wikidata en VIAF, voor iedere named entity. Per named entity worden deze identifiers opgeslagen in een verrijkingsrecord, zodanig dat ze allemaal als sleutel voor dit record gebruikt kunnen worden.
Het idee daarbij was om, in afwachting van de ontwikkelingen op dit gebied, niet te snel een keuze te maken voor één specifieke identifier. Echter, in veel gevallen bleek de Wikidata identifier erg geschikt als dé identifier voor entiteiten in de krantenartikelen: Wikidata bevat meer en meer beschrijvingen, is niet beperkt tot een specifiek domein (zoals VIAF), is niet taalafhankelijk (zoals DBpedia), en bevat veel links naar andere databronnen en wordt daar ook deels door gevoed.
Gemak en nieuwe mogelijkheden
Deze ‘convergentie’ naar één type identifier levert gemak en nieuwe mogelijkheden op. Door alle entiteiten van een Wikidata identifier te voorzien en deze samen met de tekst van het krantenartikel te indexeren, kan gebruik gemaakt blijven worden van een conventionele, voor tekst geoptimaliseerde, zoekmachine. Maar in plaats van het zoeken op een mogelijk ambigue naam (de ene Einstein is de andere niet), met mogelijke naamsvarianten, kan nu veel preciezer gezocht worden op de Wikidata identifier. Verder kunnen systemen gebruikers eenvoudig op semantische kenmerken in Wikidata laten zoeken en de resulterende Wikidata identifiers gebruiken om in de krantenartikelen te zoeken.
Omdat Wikidata bij veel objecten ook identifiers uit andere bronnen bevat, kan het resultaat van zo’n semantische zoekopdracht gebruikt worden voor het zoeken in die andere bronnen. Zo kan met behulp van een identifier in de Nederlandse Auteursthesaurus (NTA), afkomstig uit Wikidata, gezocht worden in de KB-catalogus. De impact op een bestaande infrastructuur is daarmee minimaal.
In de research portal van de KB (www.kbresearch.nl/xportal/) worden deze mogelijkheden gedemonstreerd met de collecties ‘Newspapers +’ en ‘KB Catalogue’. De vraag doet zich nu voor of het niet handiger is dat in een lokale catalogus direct naar Wikidata gelinkt wordt in plaats van naar de lokale thesaurus indien de entiteit ook al in Wikidata beschreven is. En zo ja, dan is het misschien ook handig om entiteiten die nog niet in Wikidata zitten daar zo snel mogelijk aan toe te voegen. Zo komt dit aan iedereen ten goede.
Alternatief voor Nederlandse auteursthesaurus?
In de figuur is links de huidige situatie geschetst en rechts een mogelijk nieuwe situatie met Wikidata als centrale bron en een paar nationale bibliotheken als voorbeeld. Hierbij wordt ervan uitgegaan dat Wikidata per taal ook gevoed kan worden door de lokale DBpedia, maar dit hoeft uiteindelijk geen vereiste te zijn.
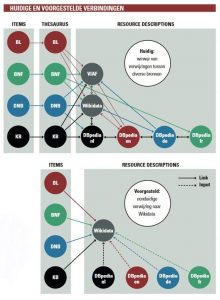
Uiteraard moeten in de nieuwe situatie alle resources waarnaar verwezen wordt in de catalogus ook in Wikidata worden opgenomen, direct, via lokale Wikipedia en DBpedia of via andere wegen. Voor een deel kan dat geautomatiseerd. Het grootste deel van de auteurs in de thesaurus heeft al een VIAF identifier. Op dit moment zitten er bij benadering 150.000 links naar de Nederlandse Auteursthesaurus en bijna 1 miljoen links naar VIAF in Wikidata.
Overigens hoeven niet per se alle thesaurus-achtige verwijzingen een Wikidatalink te zijn. Voor bijvoorbeeld een termenlijst of andere concepten, die niet of nog niet in Wikidata voorkomen, zal men een eigen, lokale thesaurus willen beheren. Deze links kunnen in een bibliografisch record ook gemengd met Wikidata identifiers gebruikt worden. Waar het om gaat, is dat ‘dingen’ waar wereldwijd naar verwezen kan worden, zoveel mogelijk dezelfde identifier (link) hebben. Met andere woorden: convergentie naar minder verschillende identifiers, voor zover dat redelijkerwijs mogelijk is.
Voor bibliografische records die een link naar de thesaurus bevatten, wordt dus voorgesteld om die links geleidelijk aan te vervangen door links naar Wikidata. Dus voor Albert Einstein verandert de verwijzing van bijvoorbeeld data.kb.nl/068350767 naar www.wikidata.org/entity/Q937. Maar dit gebeurt ook voor andere bronnen, van bibliotheek tot ruimtevaartorganisatie NASA. Indien gewenst, bijvoorbeeld om afhankelijkheid van Wikidata te voorkomen, kan een lokale thesaurus gebruikt blijven worden als een soort ‘voorportaal’ naar Wikidata. Hierin kan dan wel gebruik gemaakt worden van (een deel van) de Wikidata identifier, bijvoorbeeld data.kb.nl/urn:wikidata:Q937 voor een beschrijving bij de KB of data.bl.uk/urn:wikidata:Q937 voor een beschrijving bij de British Library.
Het gebruik van Wikidata als vervanger van de nationale thesauri hoeft niet strijdig te zijn met de nationale bibliotheek als betrouwbare bron. Integendeel: nationale bibliotheken kunnen hun rol juist beter vervullen als ze gezamenlijk verantwoordelijkheid nemen voor de invoer van de voor hen relevante data in Wikidata en optimaal gebruik maken van de grote rijkheid van Wikidata en het grote deskundig publiek. Als nationale bibliotheken niets doen, neemt de waarde van de eigen thesaurus af ten opzichte van het veel rijkere Wikidata. Door te anticiperen op deze trend en de veranderende informatiewereld, de concrete invulling even buiten beschouwing gelaten, kunnen nationale bibliotheken beter hun rol blijven spelen.
Onderscheid
Het manipuleren van linked data identifiers voor zogenaamde niet-digitaal opvraagbare entiteiten, zoals hier voorgesteld, moet onderscheiden worden van het gebruik van identifiers voor opvraagbare digitale content zoals:
- digitale representaties van bijvoorbeeld een publicatie;
- werken, gekenmerkt door bijvoorbeeld een DOI (Digital Object Identifier), waarvan meestal een of meer digitale representaties beschikbaar zijn.
Voor links naar opvraagbare digitale content (1) wordt niet voorgesteld om hier ook Wikidata identifiers te gaan gebruiken. Het gaat hier immers echt om een link naar concrete content en dezelfde content op een andere plek zal een andere link hebben. De tweede vorm van identifiers (2), zoals een DOI, identificeren het werk en niet de digitale representatie. Ook hiervoor wordt niet gepleit om Wikidata identifiers te gaan gebruiken, omdat hier meestal geen sprake is van verschillende identifiers voor hetzelfde werk. Dergelijke publicaties kunnen gevonden worden via de DOI, ISBN (International Standard Book Number) et cetera. De concrete digitale representaties hebben dan weer een lokale URL.
Tot slot
Als iedereen voor dezelfde entiteit, zoals een persoon of plaats, dezelfde Wikidata identifier gebruikt, wordt het eenvoudiger om met deze identifier gethesaureerd te zoeken, ook in lokale databases. Hiermee wordt tevens zoeken op basis van semantische informatie uit Wikidata mogelijk, zoals gedemonstreerd wordt in de researchomgeving van de Koninklijke Bibliotheek. Deze voordelen kunnen ertoe leiden dat gaandeweg meer partijen gebruik gaan maken van Wikidata om entiteiten te identificeren. Ze vormen bovendien een motivatie om te investeren in Wikidata als gemeenschappelijke thesaurus.
Als bibliotheken en erfgoedinstellingen gezamenlijk verantwoordelijkheid nemen voor het invoeren en bewaken van content in Wikidata, is het gebruik van Wikidata identifiers voor de thesaurus en van Wikidata-content niet strijdig met het uitgangspunt van bijvoorbeeld een nationale bibliotheek als betrouwbare bron. Hier ligt mogelijk zelfs een nog relevantere rol voor in de toekomst: het gezamenlijk onderhouden van een thesaurus die uitstijgt boven de grenzen van landen en disciplines.
Dit artikel is op persoonlijke titel geschreven. Theo van Veen is onderzoeker en adviseur bij de Koninklijke Bibliotheek.
Deze bijdrage komt uit IP nr. 7 / 2016. Het gehele nummer kun je hier lezen.