In dit jubileumjaar van IP – het vakblad bestaat 20 jaar – trappen we af met een onderzoek van IDM-studenten Josine Blom, Frans Huigen en Marga Hillinga. Zij deden een trending topic-analyse op de inhoud van de afgelopen 19 jaargangen. De 20 ‘trendwoorden’ die het onderzoek heeft opgeleverd zijn gevisualiseerd door Niall MacKellar. Het geheel geeft een aardig en soms ook verrassend beeld van ontwikkelingen in ons vakgebied, zoals Eric Sieverts hieronder aantoont.
Door: Eric Sieverts
Het onderzoek
Ruim 200.000 unieke woorden en bijna 4 miljoen woorden in totaal, dat is 19 jaar IP. Drie vierdejaarsstudenten, Josine Blom, Frans Huigen en Marga Hillinga, van de opleiding Informatiedienstverlening en -management aan De Haagse Hogeschool, hebben een trending topic-analyse uitgevoerd.
Met het programma AntConc zijn per jaargang frequentietellingen uitgevoerd. Met AntConc kan informatie over context, locatie en frequentie van woorden worden gevonden, in een soort KWIC-index. Daarbij wordt van het Bag of Words Model gebruik gemaakt. Dit model onderzoekt hoe vaak elk woord in een document of tekst voorkomt (wordcounts). Er wordt bij het indexeren van de tekst geen rekening gehouden met grammatica of woordvolgorde.
Ruim 830 unieke stopwoorden zijn uit de frequentietellingen gefilterd. Per jaargang is vervolgens een top-5 aan trending topics vastgesteld. Dit resulteerde uiteindelijk in een totaal van twintig trending topics. Er is vervolgens naar statistische en contextuele ontwikkelingen gekeken. Daarbij is gezocht naar eventuele verbanden met belangrijke gebeurtenissen op informatiegebied, zoals Edward Snowden, de internetzeepbel en de opkomst van Google Scholar, Wikipedia, Hyves en Facebook. Het onderzoek was zeer arbeidsintensief.
Voor de frequentietellingen is de rekenkracht vergroot door drie computers op de gegevens los te laten. De uitgaven van IP betroffen ongestructureerde data. Hierdoor moesten na uitvoering van de frequentietelling, veelal handmatig, door middel van query’s, de contextuele ontwikkelingen in het werkveld en de gebeurtenissen in de wereld om ons heen worden geanalyseerd.
(Josine Blom, Frans Huigen en Marga Hillinga)
De visualisatie
Niall Mackeller ging aan de slag met de uitkomsten van het onderzoek. Wat hij het meest interessant vond aan het databestand van de IDM-studenten waren de grote verschillen tussen de woorden: sommige woorden waren de afgelopen 19 jaar veelvuldig te vinden in IP, andere voor een heel korte periode. Hij wilde dit verschil zo helder mogelijk laten zien. Daarnaast vond hij het belangrijk dat de verandering van een aantal woorden door de tijd heen duidelijk naar voren moest komen. Daarom heeft hij ervoor gekozen om elk woord afzonderlijk te visualiseren. Omdat er behoorlijk wat data gevisualiseerd moest worden wilde hij efficiënt omgaan met de beschikbare ruimte. Vandaar het gebruik van een variant op het cirkeldiagram.
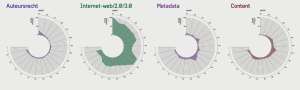
Duiding van 19 jaar IP
De visualisatie van het trendwoordenonderzoek door Haagse studenten geeft een aardig en soms ook verrassend beeld van ontwikkelingen in ons vakgebied. Weinig verrassing zat in enkele door de jaren nogal stabiele begrippen. ‘Media’ en ‘onderwijs’ kwamen regelmatig aan de orde. Voor ‘erfgoed’ geldt dat ook, zij het dat, mede dankzij nieuwe redactieleden, daarover de laatste tijd wat meer is verschenen. Ook ‘auteursrecht’ is het merendeel van de tijd stabiel, met beginjaar 1997 als grote uitschieter en een kleine toename in 2015, wellicht mede door toedoen van de juridische rubriek van Raymond Snijders. Over een aantal onderwerpen werd in de loop der jaren steeds minder geschreven. Voor ‘cd-rom’ is dat geen verrassing. Het verval zette meteen na de eerste jaargang van IP in, maar de doodstrijd heeft nog tot 2010 geduurd.
Een minder drastische daler is ‘retrieval’. Daarbij is waarschijnlijk sprake van een taalkwestie. We gebruiken het woord minder, maar we zoeken natuurlijk nog altijd. Alleen noemen we het nu ook zoeken en hebben we het over zoekmachines en zoeksoftware (al kwam geen van die woorden uit de trendanalyse). Bij ‘elektronische’ speelt waarschijnlijk iets soortgelijks. Sinds 1997 is het woord geleidelijk verder weggezakt. Kennelijk hebben we het nu vooral over ‘digitale’. Dat toont gemiddeld een lichte stijging die de daling van ‘elektronische’ aardig compenseert. Voor 2015 toont dat woord zelfs een uitgesproken piek.
Een andere daler is ‘intranet’. Na een piek in 2000, wordt er nu nauwelijks meer over geschreven. Dat we intussen alles in de cloud zouden doen kan nauwelijks een verklaring zijn. Overigens jammer dat ‘cloud’ niet uit de trendanalyse kwam en we daar dus geen statistiek van hebben.
Duidelijke groeiers zijn diensten en technieken die in de begintijd van IP nog niet bestonden. Dat geldt zeker voor ‘app’ dat in 2010 meteen hoog binnenkwam – wellicht mede door de direct gestarte app-rubriek. En uiteraard ‘Google’. In 1998 gestart, werd het in 1999 al genoemd. De echte groei kwam natuurlijk pas toen Google populair werd, sinds 2002. De uitgesproken pieken in 2005 en 2011 kon uw Google-watcher niet meteen duiden. Wel valt op dat Google nog altijd veel minder hoog scoort dan ‘digitale’ en zelfs minder dan ‘online’. Ook al zakt dat laatste begrip na een hoogtepunt in 2001-2005 nu wat weg. Nu iedereen altijd overal online is, hoeven we het er kennelijk niet meer expliciet over te hebben.
‘XML’ en ‘RDF’ zijn exponenten van de meer technische kant van ons vak. Beide pieken in 2006, wellicht doordat in die periode een rubriek over technische standaarden in IP stond. XML is sindsdien wat weggezakt. Het is intussen zo’n vanzelfsprekende basis voor alle digitale dingen, dat we het er in onze kringen nog maar zelden over hebben. RDF piekt juist de laatste jaren weer, waarschijnlijk omdat het ook de basis vormt voor linked data-technieken.
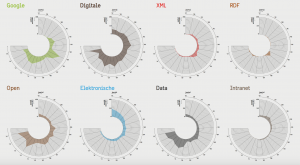
En dan wat modebegrippen. Knowledge management had zijn bloeitijd in de beginjaren van IP, maar leek uiteindelijk niet aan te slaan, totdat afgelopen jaar een duidelijke revival optrad. Een trend die je hier aan het woord ‘knowledge’ kunt aflezen. ‘Data’ is pas sinds 2009 in de mode. Voordien werd het vaak gezien als de oninteressante onderlaag van de piramide ‘data-informatie-kenniswijsheid’. Maar sinds Diederik Stapel weten we dat zonder data en datamanagement, informatie en kennis weinig waarde hebben. ‘Open’ als alledaags woordje kwam altijd al voor. Bij de groei van de laatste jaren zal het meer om ‘OPEN’ als principiële opstelling gaan. ‘Open data’, ‘open access’ en ‘open science’ vinden we steeds belangrijker.
Van ‘metadata’ zou je verwachten dat het in het tijdperk van Snowden en NSA een modeterm is, maar dat woord piekte juist al veel eerder in 2001 en 2007. ‘Content’ is zonder context wat moeilijk te duiden. Is het techniek (CMS), beleid voor content management of het moderne ‘content curation’? Bij de piek in 2004 was dat laatste begrip in elk geval nog onbekend.
Tot slot ‘internet-web/2.0/3.0’. Deze termenverzameling is duidelijk onze core business. Of misschien ‘was’? Want hiervoor lagen de toppen meteen al in 1997 en in 2005-2006. Jammer dat dit niet is uitgesplitst, waardoor we geen zicht hebben hoe gebruik van die individuele termen is verlopen.

Eric Sieverts is redacteur van IP en freelance docent en adviseur.
Deze bijdrage komt uit IP nr. 1 / 2016. Het gehele nummer kun je hier lezen.